https://www.youtube.com/watch?v=NM6lrxy0bxs
앞서본 영상은 AI 에서 Object Detection 이라는 Computer Vision의 한 분야로
2D 이미지에서 객체를 찾아내는 문제에 관한 연구분야이다.
영상 속 yolo는
2015년 vesion 1 을 시작으로 저자를 옮겨 yolov5까지 진행 중에 있다.
아래는 Object Detection의 계보라고 할 수 있다.

현재 Vision AI의 동향을 아래 링크를 통해 확인 할 수 있다.
COCO test-dev Benchmark (Object Detection) | Papers With Code
Papers with Code - COCO test-dev Benchmark (Object Detection)
The current state-of-the-art on COCO test-dev is Swin-L (HTC++, multi scale). See a full comparison of 173 papers with code.
paperswithcode.com
Object Detection은 Localization과 classification 을 같이 수행한다.
기본적인 Localization 모델에서는 객체의 위치만 검출하는 모델 예제로는
모델 마지막 부분에 FC를 사용하여 4개의 x,y,w,h 또는 x,y,x2y2를 갖는 모델로 되어있었고,
classification은 이미지가 무엇인가라는 문제를 분류하는 문제에 대한 것으로,
다수의 무엇 중에 해당 영역에 1 또는 0으로 라벨링하여 분류를 표시된다.
RCNN을 예시에서 Region proposal Localization, classification 등의 수행을 다른 Task 에서 수행하고,
Yolo의 예시처럼 하나의 Task 안에서 수행하는 End2End 방식이 있다 있다.
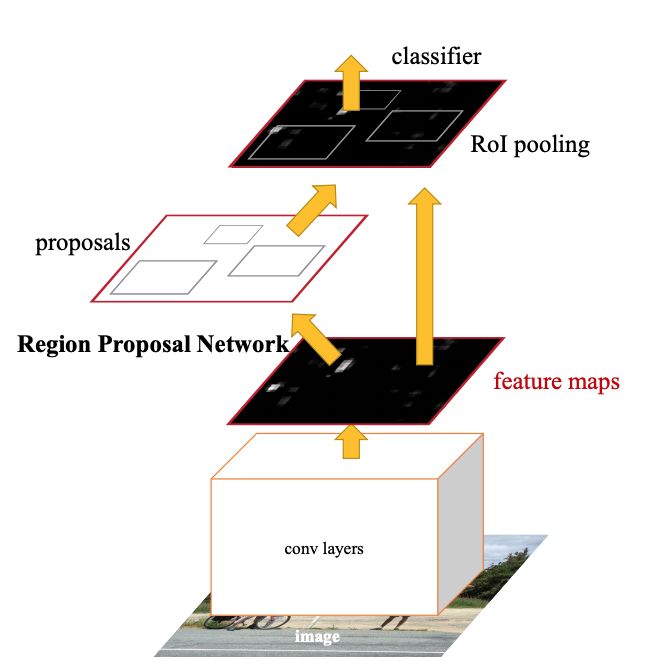
yolo의 object detection 설명 영상
Yolo에서는 출력 부분에 FC를 사용하지 않고 배치사이즈를 포함한 3차원 텐서가 출력하게 되는데.
아래와 같이 퓨처맵의 그리드에서 객체가 있을 법한 위치의 채널에 해당하는 깊이에 Localization, classification의
정보가 되도록하기 위한 학습방법에 대한 것이였다.
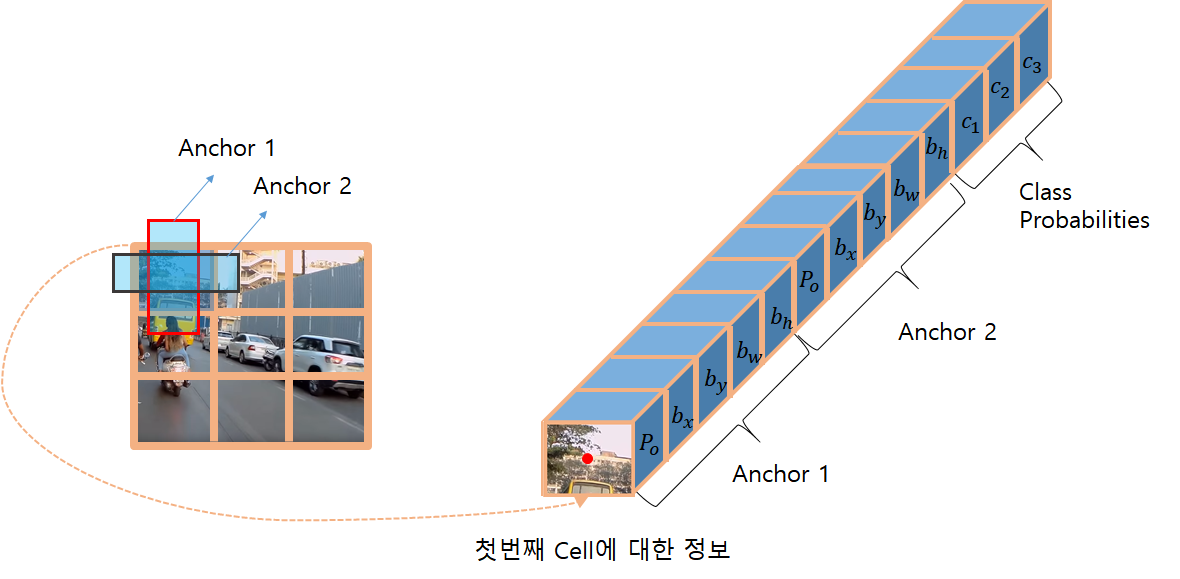
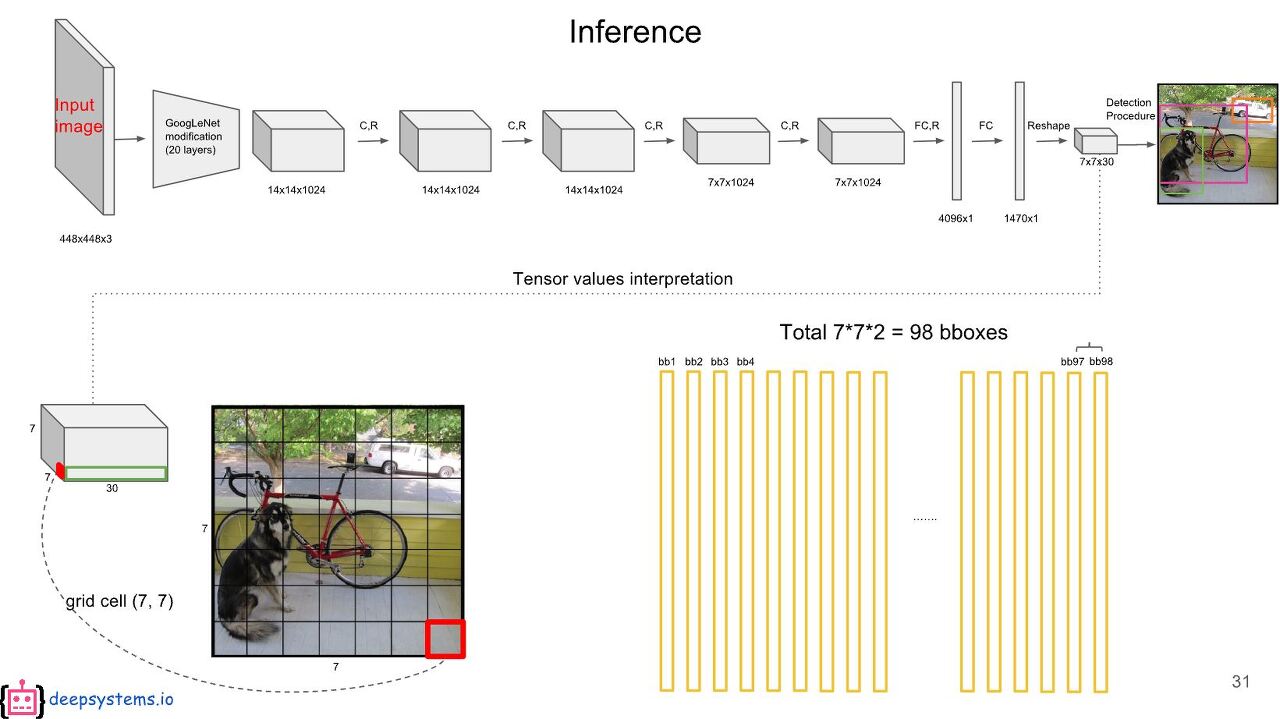
최종으로 출려되는 featrue map의 shape를 다음 그림에서는 7*7에 깊이 30의 모양임을 확인 할 수 있다.
그 경우 출력될 수 있는 BBox의 갯수는 98개 라고 이야기하는 것은 Anchor box가 하나의 그리드에 대해
2가지의 BBox가 있고, 하나의 grid에서 2개 정도의 객체를 검출하겠다라는 경우다.
Yolo에서 3차원 출력으로 문제를 보고, 다음 Loss Funtion 에도 그 의도를 확인 할 수 있다.
아래 그림 속 Loss은 Yolov4에서의 객체와 백그라운드의 구분,
bbox 의 정확도, class 구분의 3가지 문제에 대해서 3차원 Feature map과 label 간의 Cost를 구체적으로 설명한다.
두 개의 시그마는 인덱스 퓨처맵과 라벨의 인덱스 위치를 참조하고,
시그마 앞의 산식이 loss 전달에 대한 조건식과 loss의 스케일로 이루어져 있으며,
두 시그마 뒤에 있는 산식은 구체적인 loss 값에 대한 산식이다.

아래 사진은 두 개의 시그마의 인덱스 변화에 따른 라벨과 퓨처맵의 비교 연산 위치를 알려주는 그림이다.
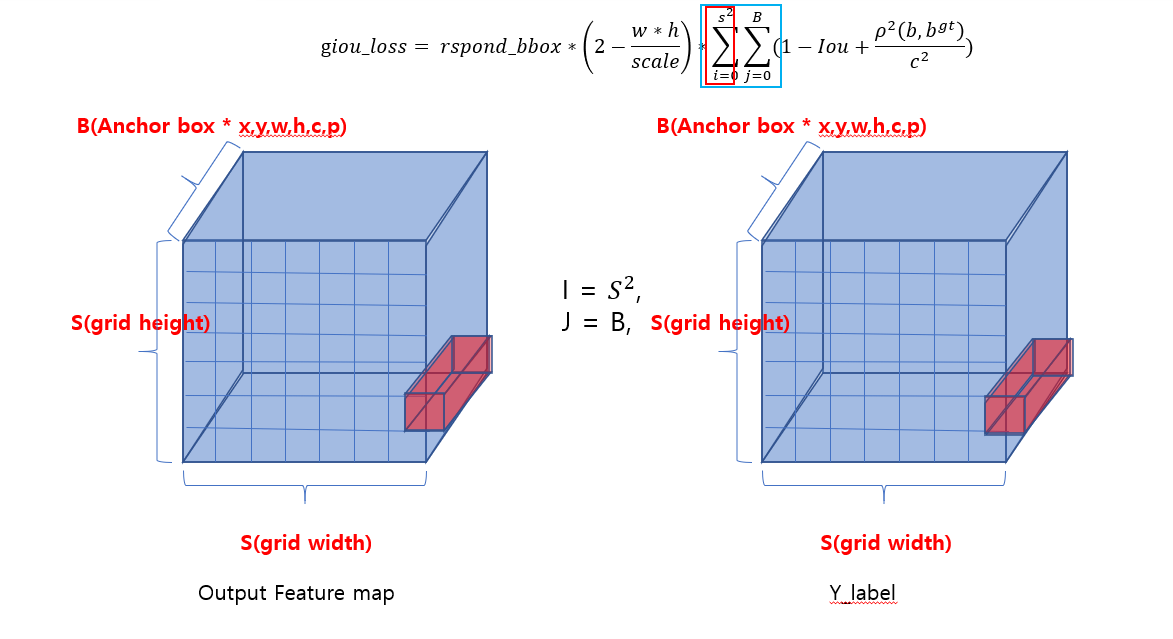
같은 그리드와 앵커 박스의 인덱스를 참조하여 시그마 뒤에있는 연산을 수행한 모든 차원에서 로스를 합산한다는 의미인데, 독자로 하여금 제대로 전달이됬을지 모르겠다.
여하간, 3차원의 출력과 라벨을 사용한다는 것을 알 수 있다.
이렇게 loss를 연산하는 과정 전에 다음처럼 Decode를 수행하는 과정이 있다.
다음 사진이 그것인데, 사진엔 없지만 연산을 편하게 하기 위해서 Reshape와 split을 먼저 수행한다.
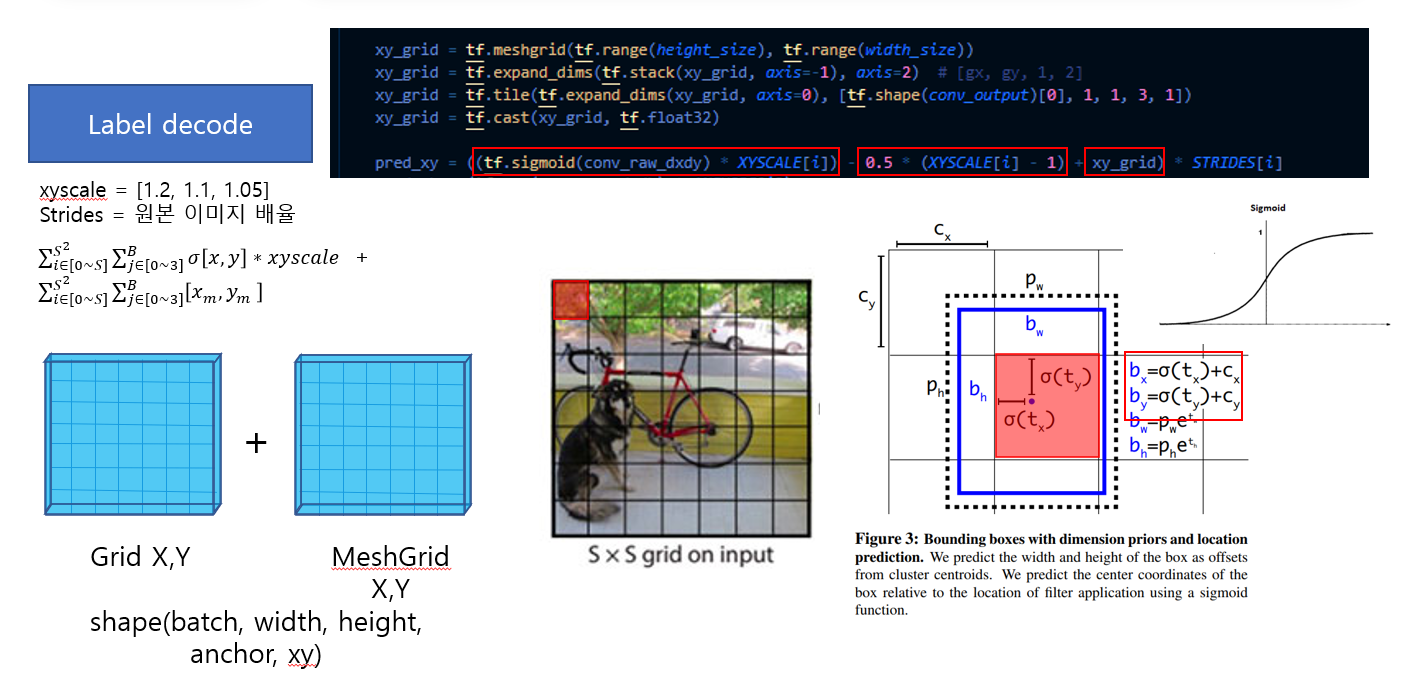
사진 속에서 meshgrid와 출력 된 feature map을 더하는데,
그리드 위치인덱스를 상수로 더해주는 연상ㅇ르 하기 때문에,
모델의 x, y 위치는 자신이 속한 그리드 셀 내에서의 좌표값에 대한 정보만을 해석하면 된다.
이 이유를 다음 그림을 설명한 후에 이야기하겠다.

그 다음 위의 이미지에서 wh에 Ahchors를 곱하는데, 이 의미는 각 featrue map의 wh 값은 exp를 거쳐 나온 값이 Anchors 의 비율을 결정하는 파라미터로 작용하며 각 앵커박스 인덱스 당 wh 가 책임지는 앵커박스의 wh가 있음을 알 수 있다.
이렇게 Decode layer와 이전 loss funtion의 구체적인 방법들은 필요한 학습 영역을 제한하여 모델의 부담을 줄이고,
모델 학습시간을 줄일 수 있고,
x, y, w, h, c, prob 등의 pred 모든 파라미터 0~1 안에서 변화할 것을 알려준다.
이점에 대해서 다시 곰곰히 생각해보면 loss funtion 상의 confidonce와 class 등 Binary Cross Entropy 문제로 추론하여 학습하는 동안 인접한 x, y, w, h 과의 gradient의 vanishing과 exploding의 문제를 동시에 해결 할 수 있음을 알 수 있다.
여하간 욜로의 핵심 idea는 이렇다.
'Study > Post' 카테고리의 다른 글
| [프로그래밍] 객체 지향 개요. (0) | 2022.02.25 |
|---|---|
| [Framework].NET Maui (0) | 2021.11.14 |
| [OS] Window10에서 11로 (0) | 2021.10.31 |
| 유한 상태머신, 유한 오토마톤FSM 또는 FA (0) | 2021.10.10 |
| [Anomaly detection] 이상 탐지 분야, 산업 현장 적용 사례 (0) | 2021.05.10 |